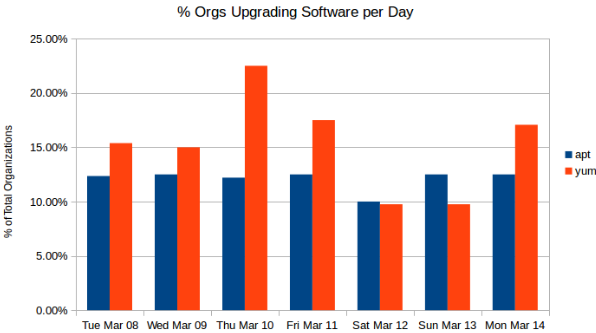
See "P.S. Some notes on the numbers" below for more information.
This is an archived copy. The original was published on the now offline Threat Stack blog.
It All Started with a Wager About System Upgrades
March 24, 2016
Sam Bisbee
It all started with a wager of the usual amount over beers with @brianhatfield. When running workloads in Cloud environments, do organizations routinely and blindly upgrade their systems? The actual means of triggering the upgrade were not questioned - chef run, hourly cron job, etc. One side took 10% or less, the other 90% or greater. While it's not important who claimed the moral victory of coming closest, it's important to remember that no one got paid (read: I lost).
The Cloud is all abuzz with immutable infrastructure, blue/green deployments, and treating servers like cattle instead of pets. In reality, successfully executing these practices is trickier than expected.
Database servers and critical load balancers are often not updated. Replacing a database server is both scary and requires a significant amount of data streaming, which is lengthy and costly. Especially if it involves streaming terabytes of data between AWS availability zones even within the same region (geo), an often overlooked section of one's budgeting.
The only way to treat systems as immutable (the goal) without replacing them (because of risk) is to not upgrade them. Sadly, this is the most traveled road.
As Verizon's 2015 Data Breach Investigations Report (DBIR) reminded us, the most commonly exploited vulnerabilities are the ones that were disclosed months or years before. Also, the rate of exploitation of a known vulnerability scales much more rapidly as it gets included in common automated scanning tools. This means that the odds of being breached due to a known vulnerability increase as it ages, typically picking up momentum months after the disclosure.
It turns out that people aren't upgrading their software enough and systems live longer than you might expect in the cloud. So start there.
At a minimum you should be applying security patches from your vendor every day, even on the weekends, automatically - look to chef, puppet, etc. While the turnaround of patches from vendors is likely long and not guaranteed, especially in open source, this might be sufficient for your needs because the latest CVEs are the least exploited.
Due to the unpredictable dwell time between public disclosure and security patch, even if you are upgrading your software every day you must get a handle on the high priority vulnerabilities in your environment. However, do not rely on CVE ratings alone. While they are a good initial indicator, they are subjective based on the instance they are found on. For example, you probably want to patch the medium severity iptables issue on your Internet facing instances before you worry about the high severity local privilege escalation on your graphite metrics box.
Simply put, stop procrastinating and practice good hygiene. The DevOps culture spawned so many tools to make this a trivial exercise for any type and size of organization, so you no longer have excuses.
Not frequently. Over a seven day period on average 13.68% of environments ran incremental upgrades of software in their environment.
See "P.S. Some notes on the numbers" below for more information.
This is not dependent on the flavor of Linux that they run. Those using yum on Red Hat based distributions (RHEL, Centos, Amazon Linux) are only 3.2% more likely to perform an incremental upgrade than those using apt on Debian based distributions (Debian and Ubuntu).
While not depicted in the graphs, the raw data surfaced a few interesting observations:
It is reasonable to expect that if a branded public disclosure were to drop during the week (DROWN, POODLE, Heartbleed, etc.) that you would see a spike in upgrades, but they probably wouldn't be automated. Instead operations teams would be logging into systems and pushing pinned upgrades.
The below graphs analyze the current agent status based on the month that they were registered in. Their online versus offline status was measured on March 17th.
The total number of registered and online agents continues to grow rapidly month over month (awesome job sales team!), while the percentage of offline agents stays relatively flat if you exclude the incomplete month of March.
Unfortunately when an agent goes offline we do not know the exact reason. Reasons could range from Blue/Green deployments, to AWS host errors (lost instances), to truly elastic workloads and test systems that are only run temporarily.
Broadly looking at agent life spans, if an agent is offline then on average it only had half the lifespan of an agent that is online. An average lifespan of about 30 days for these offline agents suggests a monthly refresh rate of infrastructure. This is a grey area from the perspective of security - it's not good because it allows for a non-trivial attacker dwell time, but it's not bad when compared to classic enterprise IT strategies.
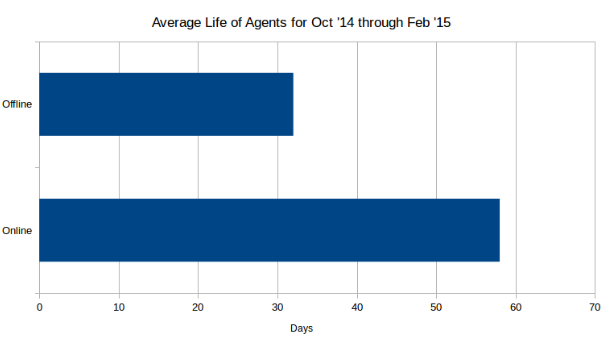
Does not include March as results are too skewed by partial month ages.
The below chart Average Life of Agent by Month They Were Registered In shows how long agents reported data for, grouped by whether they were online at the time of measurement (March 17th). We can track this because Threat Stack notes when an agent is registered and the last time that it sent data.
The two interesting trends these averages show are that agents are typically registered mid-month and are seen for the last time at the end of the month. Since all of these accounts are active and growing, this would suggest that instances are more likely to be replaced toward the end of the month, possibly due to time based release schedules or trying to bring one's bill down to meet a budget.
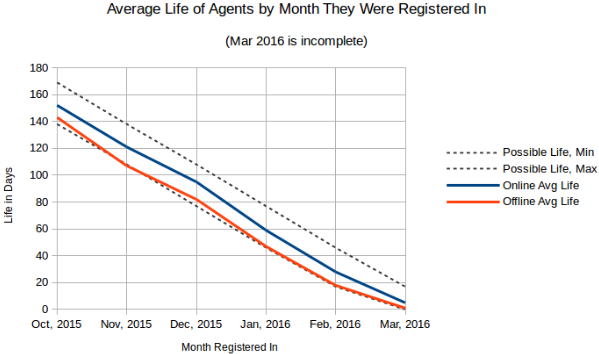
Possible Life Max is how old an agent would be if it were registered
on the first day of the month and Min is if it were registered on the
last day of the month. March looks strange because it is not a
complete month of data, but March's Online Average Life would suggest
it's trending as expected.
It appears that the actual drop off of agents is relatively linear when you look at the average age of offline agents filtered by a minimum age.
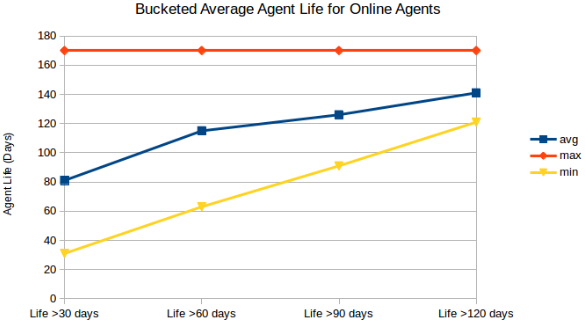
For agents registered between Oct ‘15 and Mar ‘16. The max of 170
reflects the query boundary.
Combine the next chart with the previous and we start to see the bigger picture. It's a pretty even chance whether an agent will survive for a length of time. March looks like a break out and that everything is going horribly wrong, except that we just learned that agents are more likely to churn at the end of the month. That churn is likely replaced by new agents which would last longer, rapidly increasing the percentage of online agents registered in March going into April.
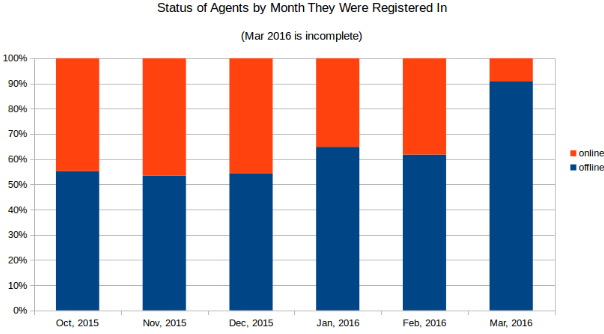
While the spike in March is certainly interesting, it is largely due to
an incomplete month's worth of data.
So, the good news is that environments are churning some their infrastructure, but unfortunately we cannot be sure why. Tracking drift of AWS AMI's is not reliable enough because it is not necessary when performing all types of upgrades.
The bad news is that this analysis shows that there is a large population of critical or high risk systems (pets) that are not patched, left vulnerable for extended periods of time.
Unfortunately apt-get is likely under reported since some organizations upgrade software by installing a specific version of it. For example, an operator might run apt-get install vim=2:7.4.052-1ubuntu3 -y which is indistinguishable from a software installation, so it was not counted as an upgrade (if it were an emacs install we'd immediately know it was a bad actor).
Dry runs and repository checks were filtered out.
The percentage of organizations upgrading their software was calculated by the number of organizations observed performing upgrades, divided by the number of organizations that had agents running that distribution on that day regardless of their age.