This is an archived copy. View the original at https://www.threatstack.com/blog/rationalizing-data-science-machine-learning-and-change-management-for-security-leadership
Rationalizing Data Science, Machine Learning, and Change Management for Security Leadership
January 11th, 2021
Sam Bisbee
At first glance data science and machine learning conflict with security best practices.
Data science and engineering teams need access to production data to do their job, yet security best practices say you must not test or develop in production, and certainly not with production data. Your technical teams know that manual changes and “quick experiments” can last forever in production, leading to unexpected issues or outages, or worse. Pre-production environments can address some of these issues, but the controls in those environments are never as strong as production, never mind the cost to copy terabytes-to-petabytes of training data, contending with customer contractual requirements for data handling, and regulatory concerns that few people understand both the technical and legal aspects of.
Data science is called data science for a reason, requiring experimentation and exploration, and those teams need access to the richest possible data to be effective. De-risking this process is tricky because unnecessarily encumbering scientists leads to attrition or the opportunity cost of un-extracted value from the business’s data. However it is difficult for security and compliance teams to not view this process as an unacceptable “build the plane in mid flight” operation.
Customer data is one of our most critical assets at Threat Stack, especially as a security company, so these are crucial details that we have thought through over the years and in particular with our public ThreatML offering.
Searching for inspiration
There is plenty written on how to implement change management in a high velocity product development organization. Engineers write code, configuration, and infrastructure control plane code, and deploy it. Using merge/pull requests in git for requests and approvals is in vogue, and maybe you hook in JIRA, but most organizations have figured out how to do this and reuse some of this machinery in their machine learning development. While this machinery is fun to look at and is great for securing speaking slots at conferences, it is the implementation of a change management approach but not an approach to change management.
Most of the prior art we found was broad strokes on AI/ML governance, deep dives on MLOps machinery by vendors, and academic analysis of adversarial attacks on algorithms and data. None of this was the practical, “hands on” information we were looking for. What ensued were many lengthy Friday afternoon discussions between our data science and security teams about how to achieve both safety and velocity for the science and product development work ahead of us - a feat only possible because of the years of hard work engineering and security had put into building a resilient platform to build such capabilities on.
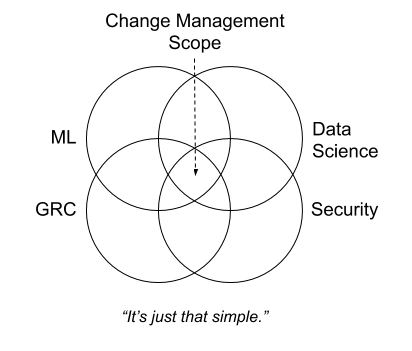
One natural place to turn for guidance was our compliance frameworks and third party reports, which for us means SOC 2, so we could eventually explain it all to our auditors. At a minimum when we are asked “show us the population of tickets for every change in production” during field testing we had better have a clean way of handling this for all of the experimentation. As you might expect SOC 2 reports do not cleanly support experimentation, but instead use the Common Criteria to require that, “The entity authorizes, designs, develops, or acquires, configures, documents, tests, approves, and implements changes to infrastructure, data, software, and procedures to meet its objectives.” Making change management useful for practitioners, not just GRC teams, deserves its own deep dive but suffice to say we have accounted for this circle in our Venn diagram by aligning development phases with the Common Criteria’s scaffolding.
It’s just that simple
The largest light bulb moment for rationalizing these disciplines came out of one of those Friday evening discussions between Dmitry Kit, our Principal Data Scientist, and myself when Dmitry asked the insightful question, “When does my exploration turn into feature development? I have to play and try different things to even come up with an idea of what I want to test and build!” This led us to orienting our change management process around the adopted term “hypothesis driven development,” using the development of a hypothesis during the Data Exploration phase as the trigger for our standard SDLC.
We will get into this more later, but it is a critical moment to realize that machine learning and MLOps supports a technically advanced and nuanced form of product development. It requires a scientific approach where you cannot pre-define the whole body of work. Leaning into the scientific aspects of machine learning and overlaying it on our existing change management process was the eureka moment we were looking for.
Is this level of effort worth it?
If this all sounds like a lot of effort then you would be correct. We strongly believe that whatever is worth doing is worth doing well, especially within our context as a threat detection and proactive risk management cloud security vendor. Security is a serious business and if we make mistakes then the best case scenario is we wasted an overburdened, understaffed security team’s time. The worst case scenario is that we mislead a security team into making the wrong conclusion resulting in the firing or incarceration of an innocent fellow human. Risk based methodologies dictate that you right-size this effort to your domain and business context.
While there are plenty of technical reasons that we have discussed elsewhere for why machine learning is not a straightforward panacea, this is the most important reason for me personally: it was not ethical to apply machine learning until we were ready, and only when counterbalanced with a rules based, deterministic approach for alerting. This combination allowed the two methods to inform one another instead of simply hoping our models were accurate. We do not operate in a domain where skipping straight to human experimentation is acceptable, especially as our customers put tremendous trust in us to be their cloud security experts. Based on internal and customer feedback on our ThreatML efforts this level of diligence and thoughtfulness in building ThreatML the right way has absolutely paid off.
Technical and organizational challenges
If your data sets are not proprietary or sensitive, or you can easily handle them with manual methods, then much of what follows may be over engineered for you. Below are the challenges that we outlined explicitly as a B2B SaaS company in the cybersecurity space.
Please notice what we are specifically not solving for here: foundational SDLC practices, MLOps machinery, specifics for the domain where you are applying data science and machine learning (ex., health care vs. cyber threat detection), and broader governance like regulation and model auditing which change management is an aspect of.
Our approach
Using the previously discussed “hypothesis driven development” lens, we extended our existing SDLC and change management process by adding a Data Exploration phase for machine learning projects. The Data Exploration phase must be performed on production data but as isolated from the production environment in a data room as is feasible. The data room could be isolated infrastructure in production, a separate AWS account with cross account IAM grants, or any other mechanism that allows for safe, read-only experimentation with tightly scoped access - a sort of virtual glovebox.
These data rooms inherit a subset of production risks since “risk follows data” but also materialize their own risks. For example, shared data querying infrastructure (production availability and performance), unsafe data handling due to a false sense of security in the data room, and the incomplete application of controls to the data room (“I forgot to Terraform apply to the data room”).
MLOps change management
We have formalized our own framework for effective MLOps change management which we are making freely available. The framework includes SOC 2 Common Criteria 8 mapping, notes on implementation of the phases, and a view on the process’s threat model with STRIDE to spark conversation. Click here for the full framework in Google Docs.
Here is how we define each phase of development:
Production: a two-phased approach
The production deployment being broken into two phases is critical for safe experimentation in production. Feature flagged experiments in sub-phase (A) must never be end user facing or impacting as they are intended solely for internal feedback. The goal is to validate that the implementation will not put production at risk (ex., due to scale) and that the team’s hypothesis has been sufficiently proven in the short-to-medium term to justify long term deployment and end user feedback. Remember, you will never achieve 100% confidence in (A) and at some point you need to release the capability to begin gathering feedback through lagging indicators to ensure your model does not break down over the long term.
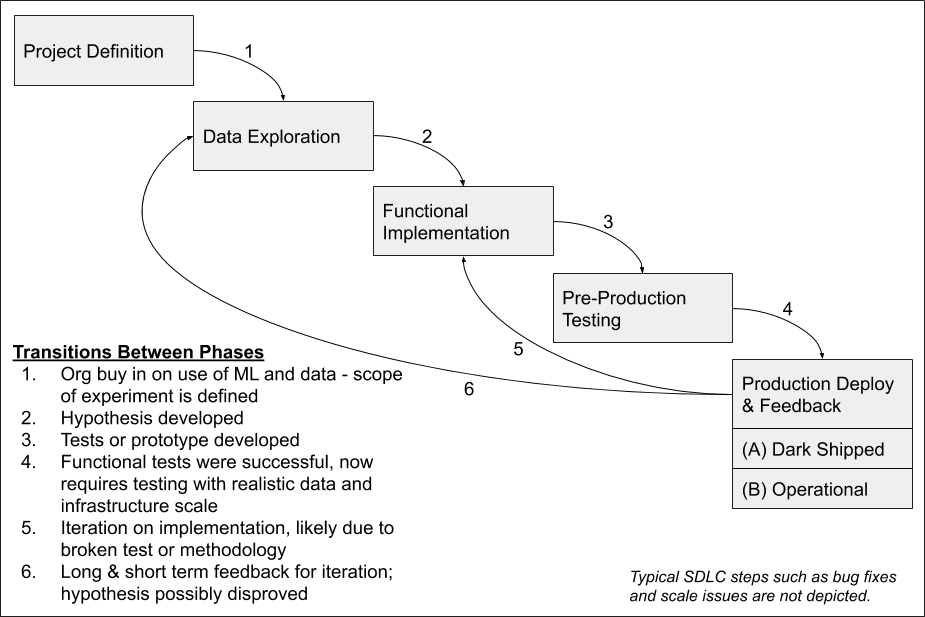
Achieving low confidence or outright disproving the original hypothesis is possibly even more important than exposing the team’s work in sub-phase (B). This is because transitioning from Production Deploy & Feedback to Data Exploration (transition 6 in the diagram) is the most expensive to the business in terms of infrastructure and opportunity cost. This is not a new concept in product development, but it requires highlighting because it is often so uncomfortable to iterate this way in production. Leadership should use this process to encourage teams to ship their experiments early and often by making multiple round trips through the process for a single hypothesis to fail fast and reduce opportunity cost. Engineering and operations teams must ensure their infrastructure supports this release velocity and that the machine learning infrastructure is sufficiently isolated to contain production issues.
It may be helpful to think of the production sub-phases as end user testing like any other product capability. Feature flagging functionality allows you to build internal confidence, sharing results with internal subject matter experts for feedback before showing early results to customers who have opted into testing and understand your feature flagged confidence level. Once you have reached your established threshold of confidence you begin to expose the capability to all customers, transitioning to sub-phase (B) for long tail analysis and feedback.
One of the ways in which we accomplish this division is by isolating the machine learning infrastructure from the rest of the platform, leveraging our existing data access layer (DAL) platform pattern to expose results to mid and higher tier services for further processing and display. The DAL also helps us solve the multi-tenant model problem, allowing us to selectively pass subsets of results, perform tenancy checks, and otherwise filter results for quasi-identifiers before displaying them. Whenever possible we opt to simplify this problem by deploying single tenant models, only leveraging multi-tenant models if there is a clear benefit. The rest of our platform has multiple layers of authorization and tenancy checks for external and internal readers that we were able to leverage “for free” by using the DAL pattern.
A note on priors
One machine learning detail where customer data and other sensitive information can potentially leak is the model’s priors. In our case this could include information for specific tenants or patterns of behavior we have learned over the last six plus years of operating Threat Stack. For example, defining a certain unique piece of software’s odd behavior, classifying a series of events as a likely deployment vs suspicious activity, or handling of a specific customer’s software. These priors may begin to leak customer information (how they deploy, their software names, risky behavior, etc.) or could be used to attack the model itself. Currently we treat priors like sensitive application configuration, leveraging the same mechanisms for configuration life cycle and peer review; this will likely evolve over time with our MLOps infrastructure.
A note on threat modeling
The framework we are sharing includes some early threat modeling work with directional qualitative commentary. This is not meant to be comprehensive for your or Threat Stack’s environment, and does not include attacks on algorithms and data. It is meant as a starting point to spark teams’ discussions on building more resilient MLOps infrastructure and machine learning based capabilities. We used STRIDE because it neatly buckets areas of concern for our teams to rationalize against the phases of development, making communication with non-security practitioners easier, but there was no other deeper meaning to its use.
If this is an area of interest for you, particularly in the areas of attacks against models and training data itself instead of just a change management lens, then I highly recommend Microsoft’s security engineering documentation on Failure Modes in Machine Learning and Threat Modeling AI/ML Systems and Dependencies.
Wrapping up
On a personal note, going back to the summer of 2014 I have been asked time and again why we did not leverage machine learning earlier in our product’s timeline. We always knew that machine learning would be leveraged at some point, but its use was not going to be purely for a buzzword boost in the market. It was going to be intentional, right sized to our domain and customers’ risk appetites, and focused on answering specific questions that we knew machine learning was well equipped to answer. If your product outcomes or maturity do not matter, then none of this is relevant to you.
Data science is not new, but the methodologies for operationalizing machine learning into products and services are. When we were designing ThreatML we knew that we needed a more intentional and methodical framework in order to orient conversations across product management, engineering, data science, and security. We hope that the ideas presented here provide a logical starting place for you to begin discussions with your own teams, protecting data, infrastructure, and users while enabling your data science and machine learning teams to rapidly experiment with hypothesis driven development.