This is an archived copy. View the original at https://www.threatstack.com/blog/why-alerts-per-day-is-a-misleading-metric-for-security-teams
Why Alerts per Day is a Misleading Metric for Security Teams
January 12th, 2021
Sam Bisbee
Over the last six and a half years we have worked with thousands of companies of all sizes and maturities on implementing threat detection for their cloud environments, and we’ve probably discussed just as many program metrics. Inevitably a workforce capacity metric like “alerts per day” will be brought up. This is a critical moment on a security team’s journey in determining whether they truly want operational security or whether they simply want to check a box to satisfy their compliance team’s assessment criteria: do they want to see 100% signal or 100% of the signal?
Some detection vendors like to tout how many alerts they generate per day as a unique differentiator. For example, one vendor proclaims “no more than two alerts per day!” This is the “100% signal” approach, prematurely constraining visibility to make users feel good instead of actually making their teams more knowledgeable. This is a concerning approach because it hides the ground truth risk from users and their reporting to the business, a precarious situation for security teams to be in with executives and the board of directors when there is an inevitable security incident. Reporting risk to the business based on a workforce constraint as a key result metric would be like your head of sales saying they only need two marketing qualified leads (MQLs) per day because that is all their team can handle, confusing needs and results (MQLs) with capacity (how many MQLs can be worked by current staff).
Artificially constraining your point of view to two alerts per day does not tell you how many alerts you could have or should have investigated. As with any backlog you need to understand where the long poles are (tech debt indicators or alert tuning opportunities), whether there is unknown risk that you need to remediate or accept (feeds the task backlog and risk register), and whether you should invest more in headcount versus automation to action the alerts that you think you should pay attention to (business case for budget based on operational data). Unfortunately security leaders have become embarrassed of their backlogs and metrics, often because they want to be perceived as perfect or “unhackable” to their peers, when they should instead represent their backlog in a manner similar to engineering and product leadership.
Before continuing we should try grounding the alerts per day metric in something foundational.
What are the objectives of threat detection?
While this depends on your program’s context, threat detection has three foundational objectives:
What is the right number of alerts per day?
If we use a metric then we must understand what its desired state is – ie., what are we optimizing for? Most teams who use alerts per day as a goal setting metric are optimizing for one of two of the below desired states.
First is a state of “zero alerts.” Simply put, a monitoring system which consistently reports zero alerts is only validating that the monitoring system is offline or malfunctioning. All monitoring systems require some form of regular human interaction to be effective over time.
Even if this is what you actually want, it is an impossible result that hides the amount of investment required to maintain a low number of alerts per day. You will have to continue applying resources to tuning and investigation even if you never change your environment because changes happen naturally over time (ex., third party updates its DNS records). Zero alerts does not mean that there is zero risk or zero incidents in your environment, and it is a continuation of the fallacy that you can build an impenetrable environment.
Second is a state of a “perfect number of alerts per day.” This usually aligns with the “we only want signal” philosophy that looks great in management presentations but suggests inexperience. There is no realistic method to determine this “perfect number” as to do so would require such a depth of knowledge of every potential adversary and real time intelligence on their activity as to be ludicrous for even those with the largest cybersecurity budgets and staffs.
There is a grab bag of other questions you must contend with if you believe there is a “perfect number” of alerts you must process each day. For example, how will you know the difference between signal and noise if you never see noise? Does this not mean that you must allow some amount of noise into your alerts and therefore your “perfect number” of alerts is a fallacy?
The state of a “perfect number of alerts per day” is an asymptotic metric at best and at worst a board meeting trap for inexperienced security teams.
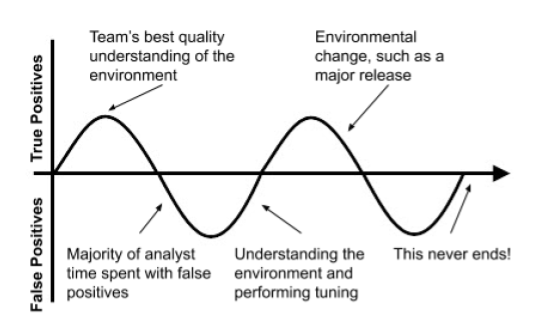
Then what do we do about false positives?
Yes, someone will have to spend time investigating and suppressing false positives; this could be an internal resource or a managed service team like Threat Stack’s Oversight SOC. This is part of the regular maintenance of a monitoring system, especially if it is watching your environment across both breadth and depth.
Why is this to be expected and accepted? The short answer is that false positives tell us what true positives look like. This is similar to an animal or human becoming aware of different sounds in the woods – you need to know what the woods normally sound like to detect a change that may indicate danger. Ironically you should be hoping that your team only spends its time with false positives, as a true positive would suggest a meaningful risk or security incident in your environment.
These optics are especially frustrating to leaders because false positives may take longer to investigate than true positives. Most true positives are blindingly obvious – no, your web server should not be downloading and executing software out of /tmp, your intern should not be accessing database configuration files, and there is no reason for Bob to be copying private keys to his laptop. Those types of true positives are few and far between though, and the majority of your time will be spent in the gray area, of scary looking AWS CloudTrail events and new system behaviors. This work takes experience, tooling, and usually minutes to tens of minutes of an experienced analyst’s time per investigation.
Strong security leaders will realize that there is money to be made with these donut holes by leveraging that human understanding of the environment to proactively de-risk it, ideally while providing additional value to the organization. For example, Alice has been working triage in the SOC for a few months and wants to better attribute actions in production to employees, but account access is unnamed using shared accounts. This behavior is also contrary to security best practices, so she escalates the risk and works with the operations team to prioritize and configure named account access. Alice begins reviewing the new data she is receiving, now with usernames based on actual employee names, only to realize that over 80% of the logins are by Bob to manually run reports for the business. Bob’s process for accomplishing this task seems unnecessary cumbersome and risky, so Alice works with engineering to implement a simple dashboard in the company’s existing systems for Bob to more quickly and safely access the data he needs. Alice may now request to have Bob’s production access revoked as he no longer needs it, while Alice works to understand the remaining production access. Alice also better understands how Bob and his team work, and if they show up in her data again she will be better equipped to investigate and handle it.
This is an example of a high functioning security operations center, leveraging both true and false positives to improve the business (improving Bob’s task completion time) by de-risking it (less production access). This is far more impactful than chasing a metric like alerts per day because you are leveraging ground truth to make your environment more resilient to known and unknown threats, and your employees’ 2am on-call mistakes.
Some metrics worth starting with instead
Ideally you are leveraging a grouping that’s above alerts, such as cases, which allows your analysts to rationalize a body of work. It is rare that a single alert is worth investigating on its own without any other alerts, making their grouping relevant for both detection and workforce metrics. Managing alerts per day instead of cases per day is like an engineering manager looking at commits per day instead of features progress per day.
Whether you adopt a case based process or not, here are some impactful metrics worth considering when building your threat detection program. Most of these metrics should be viewed per analyst in addition to across the team, equipping managers with topics for their one on ones with analysts.
Some of these metrics are still workforce related, but unlike alerts per day these metrics have greater fidelity and speak to a richer story. Alerts per day is just a raw processing metric that must be contextualized with metrics like the ones above to be informational.